Tamás Ferenc: Big Data –
avagy az óriási adatmennyiség és annak feldolgozása
A "Big Data" fogalma egy komplex technológiai környezetet jelent, amely egyaránt tartalmazza az adatokat, a tároláshoz szükséges szoftvereket, hardvereket, valamint a hálózati eszközöket is, amelyek az óriási adatmennyiség feldolgozását teszi lehetővé. Ezek az adatállományok már olyan komplexek, hogy közelítő viszonyban sincsenek sem a hagyományos Excel-táblázatokkal, sem a kisebb adatmennyiséget feldolgozni képes Access-állományokkal. Leegyszerűsítve a "Big Data" fogalom a nagyon nagy mennyiségű és igen gyorsan változó adatmennyiség kielemzését és feldolgozását jelenti – sokszor akár valós időben. A 2010-es évek elejének egyik legizgalmasabb témája a „Big Data” volt, amiből pár év alatt egy egész iparág nőtt ki a 2020-as évekre.
A "Big Data" alkalmazása mellett szól az is, hogy egy bizonyos (igen nagy számú) adatmennyiség felett már olyan alaposan meg lehet ismerni egy adatfolyamatot, hogy jó eséllyel meg lehet jósolni a folytatást. Lehet ez akár ipari termelés, közlekedés, adott termékkör fogyasztási szokásai vagy akár emberi viselkedés is. Így a "Big Data" technológia segítségével új korszak nyílt a design, az orvostudomány, a szoftverfejlesztés, valamint a marketing előtt is.
Maga a "Big Data" nem egy konkrét technológia, hanem régi bevált és új technológiák összessége. Ezek a technológiák képesek biztosítani a különféle rendszerek által a hálózatokra, illetve az internetre öntött irdatlan mennyiségű adat feldolgozását, , illetve a keletkezett információkból való adatnyerést, valamint kielemzést. A "Big Data" legfontosabb jellemzői angolul a 3 V:
- Volume: nagyon nagy adatmennyiség,
- Velocity: nagyon gyors adatfeldolgozás,
- Variety: nagyon változatos adatok.
A Microsoft oldalain találtam egy jó ábrát a folyamat részeiről, illetve azok összefüggéséről:
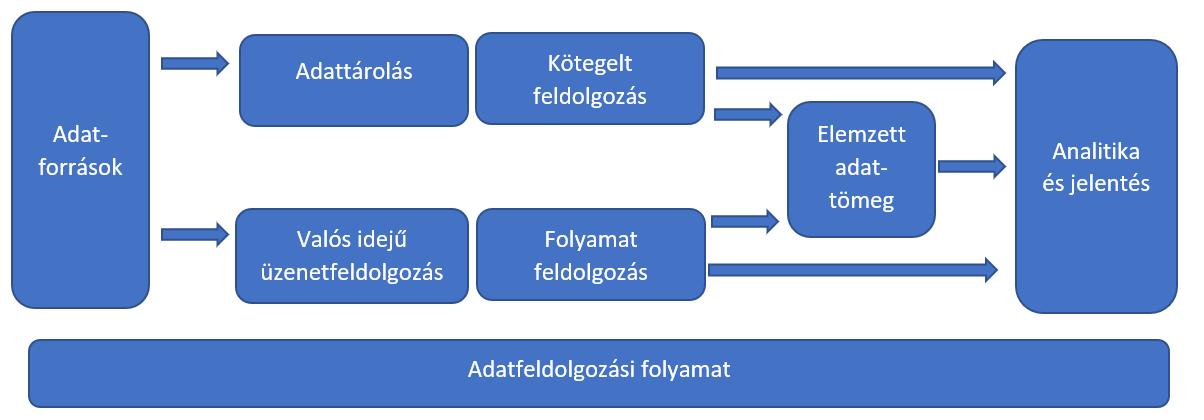
Ábra eredetije: https://docs.microsoft.com/hu-hu/azure/architecture/guide/architecture-styles/big-data
A három V részletesebben
- Volume: Az adatok mennyisége. Big Data esetén igen nagy mennyiségű, jellemzően strukturálatlan adatot kell feldolgozni. Ezek lehetnek többek között ismeretlen értékű adatok (pl. Twitter-adatfolyamok), weblapon vagy alkalmazásból kiolvasott kattintások, esetleg szenzorképes berendezések értékei. Kisebb igénybevétel esetén ez pár GB-ot jelent óránként, de egyes szervezeteknél ez könnyedén elérheti a percenkénti több száz GB-ot, vagy akár a több PB-ot is.
- Velocity: a sebesség a gyors adatfogadás és a minél gyorsabb feldolgozás képessége. Az adatfolyamok többsége általában direkt a gép memóriájába érkezik, így célszerű az azonnali feldolgozás is. Ehhez persze szükség van megfelelő sebességű adatfolyamra, valamint elegendően nagy memória-kapacitásra is. Kerülendő az adatfolyamatok átmeneti tárolása (akármilyen adathordozón), helyette előtérbe kerül az internetes feldolgozás, pl. felhő- vagy köd-alapon. A legtöbb internet-kompatibilis folyamat valós vagy közel valós időben dolgozza fel a bejövő adatfolyamatokat, így szinte azonnali reakciót vagy cselekvést képes javasolni.
- Variety: A rendelkezésre álló adatok sokfélesége. A hagyományos adatok általában jól strukturáltak (gondoljunk itt egy sima Excel táblára vagy egy Access adatbázisra). Ezzel szemben a „Big Data” adatai többnyire rendszertelenek, jellemzően strukturálatlan formában özönlenek az adatfeldolgozó központhoz. Az így bejövő adatok (pl. szöveg, hang, kép vagy videó) többnyire egy előfeldolgozóba kerülnek, ahol megfelelő előkészítés után már alkalmasak lesznek a hagyományoshoz közelítő strukturált feldolgozásra.
Az elmúlt években két újabb „V” betű jelent meg: érték (value) és megbízhatóság (veracity). Az egyes adatoknak ugyanis értéke van, így kerül képbe az adat megbízhatósága is. Mára a „Big Data” önmaga is jelentős tőkévé vált. Gondoljunk itt a világ legnagyobb IT-vállalataira! Mire is lennének MI-k által feldolgozott Big Data adathalmaz villámgyors elemzése nélkül? Gondoljunk itt akár egy Facebook adatfolyamra, akár egy Youtube lejátszási vagy reklám-listára. Más részről érdemes pár szóval megemlíteni az MI-k által összeválogatott személyes hírfolyamokat is. (pl.: Androidos telefonoknál Google News vagy MS Edge alapértelmezett hírfolyam)
A közelmúlt exponenciális technológiai fejlődése radikálisan csökkentette az adatfeldolgozás és az adattárolás költségét, így minden eddiginél egyszerűbb lett ezek feldolgozása is. A drasztikusan megnőtt adatmennyiség hatására most jóval olcsóbb, elérhetőbb, pontosabb és precízebb előrejelzés készíthető.
Azonban a Big Data nem csak elemzésekből, illetve az ahhoz szükséges adatfeldolgozásból áll. Ez egy teljes folyamat, amely igen éleslátó elemzőket, jó érzékű üzleti döntéshozókat és vezetőket igényel, akik megfelelő időben fel tudják tenni a megfelelő kérdéseket és képesek a megfelelő válaszokat is megadni, valamint alkalmasak a megfelelő döntések meghozatalára.
Az internetes adatfeldolgozás múltja és jelene
Több korszakra oszthatjuk fel a számítógépes adatfeldolgozást. A számítástechnika megjelenésekor (1950-es és ’60-as években) az adatok leginkább szekvenciálisan, azaz sorban egymás után voltak csak elérhetők. Az akkori jellegzetes tárolási technika a mágnesszalag volt. A ’60-as és ’70-es években kezdtek egyre nagyobbak lenni az adathalmazok, így kialakultak az első adatközpontok. 
A következő korszakban elterjedtek a relációs adatbázisok, illetve az ezeket feldolgozó SQL-nyelvek. Ám ezen adatbázisok létrehozása és fenntartása meglehetősen költséges, időigényes és lassú volt (’70-es és ’80-as évek). Ekkor kezdtek megjelenni az adattárházak és a bennük feldolgozásra kerülő "Entity-Relationship" modell. A relációs adatbázisok használata a ’90-es évektől vált teljes körűen elfogadottá.
Nagyjából ilyenkor, 1998-ban alkotta meg maga a "Big Data" fogalmát John Mashey. (Kép forrása: https://www.quora.com/Who-coined-the-term-big-data)
2005 körül a programozók kezdték felismerni, hogy az egyes felhasználók mekkora adatmennyiséget generálnak pl. Facebook-on, Youtube-on és egyéb online platformokon. Ugyanebben az évben fejlesztették ki a Hadoop-ot, egy nyílt forráskódú keretrendszert, amelyet kifejezetten nagy adathalmazok kezelésére és tárolására fejlesztettek ki. A NoSQL platform is akkoriban kezdett népszerűvé válni.
Utána következtek a skálázható hardvereken elterjedt virtualizációs technikát használó relációs adatbázisokon alapuló óriási adatfarmok, illetve adattárházak. A tárolókapacitások radikális növekedésével megjelentek a BLOB-ok (binary large objects), illetve az objektum orientált adatbázis-kezelő rendszerek. Gazdaságossá vált az adatmennyiség valós idejű feldolgozása, amely az egyre jobban elterjedő optikai hálózatok sebességének köszönhetően radikálisan felgyorsult. Jó hasznot termelő üzletté viszont leginkább a felhő-alapú számítási rendszerek elterjedésével vált nagyjából a századvég idején. A nagy teljesítményű hardverek szolgáltatta irdatlan adatmennyiség feldolgozására egészen új technológiákra volt szükség a már meglévő adatbányászat és tartalom-menedzsment eljárások mellett. Ilyen például a párhuzamos adatfeldolgozás is, illetve a szerverfürtökön lévő párhuzamos, kötegelt futtatás.
A nyílt forráskódú rendszerek, mint a Hadoop (mostanában inkább a Spark) komoly fejlesztése elengedhetetlen volt a Big Data növekedéséhez, mivel ezek megkönnyítették és olcsóbbá tették az egyre növekvő adatmennyiség tárolását, illetve feldolgozását. A felhasználók azóta is egyre növekvő mértékű adatmennyiséget generálnak, de ezt immár nem csak emberek végzik.
A dolgok internetjének (IoT = Internet of Things) megjelenésével egyre több eszköz csatlakozik a világhálóra és ontja az adatokat. Ennek köszönhetjük, hogy a felhasználók interakciói, illetve szokásai is feldolgozhatóvá váltak. A gépi tanulás megjelenése még több adatot hozott forgalomba.
Másik példa egy nagyobb weboldal látogatottsági statisztikáinak feldolgozása: itt lényeges a látogatók száma mellett az összes adat, amit a látogatókról meg lehet tudni, például: böngésző típusa és verziója, operációs rendszer, platform, képernyő felbontása, kattintások gyakorisága, oldalon maradás hossza, rátalálás típusa, aktivitás az oldalon, a megrendelések kielemzése, …
Ezek alapján már lehet személyre szabott reklámokat és ajánlatokat is adni, illetve a felhasználót legjobban érdeklő témákat lehet előre sorolni. (Lásd: Facebook vagy Instagram idővonal)
Másik példa a céges hatékonyság fejlesztése. Érdemes mérni, hogy a céges autók mennyit futnak és erre mennyi benzint számolnak el, így kimutathatók az esetleg hibás beállítások vagy a fogyasztást manipuláló alkalmazottak. Az is mérhető, hogy hány hívást kap a céges helpdesk egy műszak alatt és azok milyen hosszúak, valamint érdemes mérni a betelefonálók elégedettségét is. Lehetőség van azt is mérni, hogy egy munkaállomás miként teljesít egy adott napon. Így rá lehet arra is jönni, hogy mi okozza a kiugrásokat, illetve a hullámvölgyeket, melyek segítségével a munkaszervezést lehet hatékonyabbá tenni.
Maga a Big Data teljesen új korszakot nyitott a design, az orvostudomány, a szoftverfejlesztés és akár a marketing előtt is.
Nehézségek
Maga a feldolgozás már hatalmas számítási kapacitást feltételez. Ehhez még hozzájárul az is, hogy a forrás gyakran nem egy fix adathalmaz, hanem egy állandóan változó, örökösen újratermelődő adatsor. Ehhez nem elegendő egy gyors kapacitású adatfeldolgozóeszköz, hanem biztosítani kell a megfelelő adatáramláshoz szükséges elegendően szélessávú összeköttetést is. A "Big Data" előzetes elemzésben és pl. a viselkedéselemzésben is használatos. Az internetes keresés, pénzügyi trendek, betegségek terjedése, bűnözési statisztika-alapú rendészet, meteorológia, orvostudomány, genetika, komplex fizikai jelenségek szimulációja, marketing és kormányzati funkciók: ezek mind alkalmasak a nagy sebességű adatelemző funkciókra.
Régebben ezeket az adatelemzéseket jellemzően emberek csinálták meg, de ezek zömét már átvették a mesterséges intelligenciák (MI, angolul AI = artifical intelligense). Egy MI-nek elegendő kapacitása és eszköze van ahhoz, hogy pl. figyelje 20-30 tőzsde forgalmát és közel valós időben kiszűrje a megfelelő irányokat. Egy céges autóflotta irányításához is nagy segítséget adhat a megfelelően programozott MI. Azonban az előre nem látható nehézségek, véletlen adatfolyamatok miatt mindig is szükség van egy adatfelügyelőre (angolul: data scientist), aki az előre nem látható folyamatokat figyeli, illetve kiszűri azon csapdákat, amikbe az MI-k hajlamosak besétálni.
A szükséges hardver
A szenzorok és szoftverek által gyűjtött rengeteg adatnak feldolgozásához nem feltétlenül voltak meg a megfelelő eszközök az 1990-es években. Ehhez hatalmas adattárolók kellenek, mindezek megfelelően komplex rendszerben. Már régen túlléptünk a kétdimenziós (Excel-szerű) táblázatokon, illetve a hagyományos Access-szerű adatbázisokon, illetve az ezek tárolására használt számítógépeken.
Az óriási adatmennyiségek feldolgozásához elengedhetetlenül fontos a felhő-alapú tároló rendszerek megléte. Ezek a helytől függetlenül képesek a felmerült adatokat feldolgozni, illetve megfelelő kezelő rendszer esetén szolgáltatásokat/applikációkat is futtatni. Maguk a felhő-szolgáltatásokat nyújtó szerverek amúgy egyszerű, de nagy teljesítményű PC-kompatibilis gépek.
A felhő-szolgáltatások jellegzetessége, hogy helytől és platformtól függetlenek, de ez sok vállalatnak nem tetszett, így létrejöttek az úgynevezett „Fog-” (köd-) farmok, amelyek logikailag a helyi szerverek felett, de a felhő-farmok alatt helyezkednek el; míg fizikailag a helyi szerverek közelében, pl. városon belül. Szolgáltatásaik megegyeznek a felhőkével, tehát lehet sima tárhelyként is használni, de elképzelhető applikációk/programok futtatása is.
Másik, több vállalat által is jobban preferált megoldás a védett felhő-adatbázis, melyben csak az adott vállalat megfelelő védelemmel ellátott adatai tárolhatók. Ha ezt megfelelően védik a betolakodók, illetve az adathalászok ellen, akkor ez is nagyon hatékony lehet.
Ha elég sok az adat, akkor sokkal nehezebb is vele dolgozni: sok tárhely kell, sokáig tart kiértékelni, lassan fut le rajta egy hagyományos keresés, túl összetett feladat lefuttatni rajta egy szerkesztést vagy általános rendezést. Ráadásul ott van az adatbiztonság egyre növekvő problémája.
Ezen problémák miatt a Big Data adatai nem egy bizonyos állandó adatbázist jelentenek, hanem pl. egy bizonyos forrásból állandóan (újra)termelődő adatsort, amiből aztán mintavételezéssel lehet megfelelő (valódi) adatokat kinyerni. Ezeket aztán már lehet a hagyományoknak megfelelő módon feldolgozni!
A Big Data prediktív elemzésben és pl. viselkedéselemzésben is használatos. Ilyenek lehetnek például: az internetes keresés, pénzügyi trendek, betegségek viselkedése és terjedése, bűnözési statisztika-alapú rendészet, meteorológia, genetika, orvostudomány, komplexebb fizikai jelenségek szimulációja, marketing és egyes kormányzati funkciók.
A megfelelő elemzésben fontos az irreleváns adatok kiszűrése. Például az óránkénti hőmérséklet mérésekor több száz helyről 15-20 fok közötti értékeket kapunk, de hirtelen beugrik egy 47, vagy egy -12 fokos érték, akkor a megfelelő adatelemző rendszerrel ezt ki kell szűrni, mivel ezek nem lehetnek valódi értékek, hanem minden bizonnyal csak mérési hibák.
Fontosabb fogalmak
A cikk ezen részénél erősen támaszkodtam az alábbi cikkre: https://docs.microsoft.com/hu-hu/azure/architecture/guide/architecture-styles/big-data
- Adatforrás: Minden Big Data megoldás egy vagy több adatforrást tartalmaz, Gyakorlatban ebből vagy ezekből nyeri a feldolgozandó adatmennyiséget. Ezek között lehetnek: alkalmazások adattárai, adatbázisok, statikus fájlok (pl.: rendszernaplók), valós idejű adatforrások (jellemzően IoT eszközöknél).
- Adattároló: A kötegelt feldolgozáshoz szükséges adatok tárolására alkalmas eszköz vagy tároló. Lehet egy klasszikus adatforrás (HDD, SSD, egyéb offline eszköz), de egyre inkább a növekvő adatmennyiség a megkívánt feldolgozási gyorsaság miatt egy internetes forrás. Az ilyen tárakat „data lake”-nek (kb.: adattó) nevezik. Ezek megoldásai MS-platformokon: Azure Data Lake Store vagy Azure Storage.
- Kötegelt feldolgozás: az igényelt adatmennyiség óriási, így a hagyományos feldolgozási módszerek rendszerint csődöt mondanak. A Big Data megoldásoknak szükségük van megfelelő előszűrésre, adatelemzésre, összesítésre, illetve egyéb finomhangolási műveletekre. Ezek a feladatok tartalmazni szokták a megfelelő adatforrások beolvasását, feldolgozását, további a kimenetbe való előkészítést és esetleges kiírást is. Az MS által javasolt megoldások: U-SQL-feladatok futtatása az Azure Data Lake Analyticsben; Hive-, Pig- vagy egyéni Map/Reduce-feladatok használata egy HDInsight Hadoop-fürtben; illetve Java-, Scala- vagy Python-programok használata egy HDInsight Spark-fürtben.
- Valós idejű üzenetfeldolgozás és -betöltés: Nagyon sok Big Data megoldás tartalmaz üzenetek feldolgozási lehetőségét is, ráadásul mindezt valós időben. Tehát lehetővé kell tenni a bejövő üzenetek megfelelő rögzítését, tárolását, valamint azok minél pontosabb feldolgozását is. Az MS által javasolt megoldások a következők: Azure Event Hubs, Azure IoT Hubs és a Kafka.
- Folyamatok (stream-ek) feldolgozása: A Big Data alkalmazásnak az üzenetek rögzítés mellett fel is kell dolgoznia, szűrnie, illetve elemzésre előkészítendő összesítenie is kell ezeket. A rendszer egy kimeneti fogadóba írja a feldolgozott (főleg valamilyen SQL-alapú) folyamatokat. Az MS Azure Stream Analytics egy felügyelet stream-feldolgozási szolgáltatást biztosít mindezen folyamatokra.
- Analitikai adattár: Sok Big Data-megoldás előkészíti az adatokat, majd megfelelő struktúrában fel is dolgozza azokat egy elemzés előkészítéséhez. Az MS Azure Synapse Analytics felügyelt szolgáltatást biztosít a felhőalapú adattárházakhoz. Az MS HDInsight támogatja az interaktív SQL-eszközök használatát, amelyekkel szintén előkészíthetők az adatok elemzésre.
- Analitika és jelentés: ez a Big Data-folyamatok összefoglalója, hiszen az egyes elemek által biztosított eredményeket fogja össze és a végfelhasználó által érthető formátumban adja ki. Ez lehet MS Excel táblázat, vagy 3-dimenziós adatelemző modell vagy egyéb BI- (üzleti intelligencia-) megoldás. MS által javasolt megoldások: Python vagy R nyelvű szoftverek. Nagy méretű adatfeltárás esetén használhatja az MS R Servert önállóan vagy Sparkkal együtt.
Példák a "Big Data" alkalmazására
- BKK Futár:  A budapesti tömegközlekedés minden résztvevője rendelkezik GPS-jeladóval, amely folyamatosan önti az adatokat a központba. Ez alapján a központ kielemzi a pillanatnyi forgalmat, a várható menetidőt, illetve a köztéri kamerák adatainak bekapcsolásával reagál az esetleges vészhelyzetekre eldöntve, hogy mikor és hol szükséges emberi beavatkozás. A megoldás egyik része egy telefonra letölthető applikáció, melynek segítségével könnyedén meg lehet tervezni az utazást. URL: https://go.bkk.hu/
A budapesti tömegközlekedés minden résztvevője rendelkezik GPS-jeladóval, amely folyamatosan önti az adatokat a központba. Ez alapján a központ kielemzi a pillanatnyi forgalmat, a várható menetidőt, illetve a köztéri kamerák adatainak bekapcsolásával reagál az esetleges vészhelyzetekre eldöntve, hogy mikor és hol szükséges emberi beavatkozás. A megoldás egyik része egy telefonra letölthető applikáció, melynek segítségével könnyedén meg lehet tervezni az utazást. URL: https://go.bkk.hu/
Androidos applikáció: https://play.google.com/store/apps/details?id=hu.webvalto.bkkfutar- A cikk írásakor az útvonaltervezésen kívül lehet venni vonaljegyet, heti- vagy havi bérletet is, valamint forgalmi információk is elérhetők.
 - Google App Engine: A Google túllépve a hagyományos keresőszolgáltatásokon nem csupán tárhelyet kínál, hanem ennek segítségével programok/alkalmazások futtatását is lehetővé teszi, valamint képes webes alkalmazások futtatására is – segítve ezzel a tárhelyen tárolt adatok, illetve dokumentumok korrekt feldolgozását. Maguk az alkalmazások egymástól elkülönítve, külön szerveren futnak, ráadásul az App Engine automatikus skálázhatóságot kínál. 1. kiadás: 2008. ápr.7.; stabil verzió: 2018.febr.7. Fejlesztési nyelvek: Python, Java, Go, PHP, Node.Js. URL: https://cloud.google.com/appengine/
- Google App Engine: A Google túllépve a hagyományos keresőszolgáltatásokon nem csupán tárhelyet kínál, hanem ennek segítségével programok/alkalmazások futtatását is lehetővé teszi, valamint képes webes alkalmazások futtatására is – segítve ezzel a tárhelyen tárolt adatok, illetve dokumentumok korrekt feldolgozását. Maguk az alkalmazások egymástól elkülönítve, külön szerveren futnak, ráadásul az App Engine automatikus skálázhatóságot kínál. 1. kiadás: 2008. ápr.7.; stabil verzió: 2018.febr.7. Fejlesztési nyelvek: Python, Java, Go, PHP, Node.Js. URL: https://cloud.google.com/appengine/
Hosszabb videó (kb. 45 perc) a Google App Engine-ről kezdőknek:
- Amazon EC2: ez röviden egy virtuális számítógép-kölcsönző. A felhasználónak lehetősége van a felhőben meglévő adatok alapján összeállítani a saját tárhely és CPU-konfigurációját, amin aztán futtathatja a saját szoftvereit, illetve tesztelheti az alkalmazásait. Így a viszonylag kicsi saját gépparkkal rendelkező cégek számára is elérhetővé válnak – virtuálisan – az óriási teljesítményű gépek. Maguk a virtuális gépek fizikailag az Amazon adatközpontjának gépein futnak. Az egyszerű webes felület lehetővé teszi a szükséges kapacitás összeállítását egy kellőképpen biztosított számítási környezetben. Fizetni csak a ténylegesen igénybe vett kapacitás kell. 1. kiadás: 2006.aug.25. URL: https://aws.amazon.com/ec2/
 - Heroku: egy klasszikus felhőplatform, amely több különböző webes applikáció összeállítására is alkalmas programnyelvet támogat. A platform kezdetben csak a Ruby nyelvet támogatta, de később ezt kiterjesztették egyéb nyelvekre is (Node.js, Java, PHP, Python, …) URL: https://www.heroku.com/
- Heroku: egy klasszikus felhőplatform, amely több különböző webes applikáció összeállítására is alkalmas programnyelvet támogat. A platform kezdetben csak a Ruby nyelvet támogatta, de később ezt kiterjesztették egyéb nyelvekre is (Node.js, Java, PHP, Python, …) URL: https://www.heroku.com/
- Talend: egy olyan felhő-platform, ami az összegyűjtött adatokat érthető grafikonokká, illetve kimutatásokká alakítja át megfelelő programozással. URL: https://www.talend.com/

- Tableau: az előzőhöz hasonló szolgáltatásokat nyújtó felhő-platform, amely adatfeldolgozási és analizáló eszközei segítségével segít az üzleti modellek megoldásában, illetve a helyes üzleti döntések meghozatalában. URL: https://www.tableau.com/

- Hadoop: egy nyílt forráskódú rendszer, ami elosztott alkalmazásokat támogat. Hatékonyan alkalmazható nagy mennyiségű, alacsony költségű, általánosan elérhető hardverből épített szerverfürtök építésére. Úgy tervezték, hogy egységes kiszolgálóktól több ezer gépig bővíthető legyen. A szervezettség miatt igen magas a rendelkezésre állás. URL: http://hadoop.apache.org/

- Tinder: az egyik legnépszerűbb mobiltelefonos társkereső oldal, ami egy igen könnyű regisztráció után finomított találatok tucatjait vagy éppen százait adja. Ehhez egy igen bonyolult algoritmus kell és ![]() a regisztrált felhasználók óriási tömege nemzetközileg. URL: https://tinder.com/
a regisztrált felhasználók óriási tömege nemzetközileg. URL: https://tinder.com/
- US Xpress Inc.: A cég logisztikával, azon belül is főleg szállítással foglalkozik. Nem csupán érzékelőkkel tömte tele a szállítókocsijait, hanem a döntéseket is automatikus mechanizmusokra bízta, így tudta optimalizálni a szükséges útvonalakat, benzin- és emberi munka árait. URL: https://www.usxpress.com/

Magyar cég a Big Datában
Az egyik legsikeresebb és leggyorsabban növekvő „Big Data”-feldolgozó cég a magyar Starschema, amely bekerült a Fortune magazin leggyorsabban növekvő cégeket felsoroló TOP500-as listájába. A budapesti székhelyű cég ügyfelei többek között az Audi, az Avon, a Bosch, az Erste Bank, a Facebook, a Shell, a NetFlix, a Raiffeisen Bank, a Vodafone, a Walt Disney,… Ráadásul jó hír, hogy elég gyakran keres (angolul jól beszélő) ifjú programozókat.
További példák
- Target áruházlánc – elemzi a gyereket váró női fogyasztók szokásait és rendeléseit. Egyszer például egy minnesotai férfi felháborodva telefonált, hogy középiskolás lánya bébivárós kuponokat kapott. Indok: az áruház előbb tudott a lány terhességéről, mint a lány apja. URL:https://corporate.target.com/
- Waze – telefonos alkalmazás, amely navigációs adatokat köz öl a telefonba épített GPS segítségével. Ötletük a közösségi megvalósítás, vagyis az úton lévők segítségével közölnek valós forgalmi adatokat – ingyen. Így válik lehetővé pl. a forgalmi dugók elkerülése. Így válik lehetővé a hagyományos útvonaltervezés mellett a forgalmi dugók elkerülése is. Kiegészítő szolgáltatások pl. traffipax-jelzés, útakadályok, sebesség-túllépés jelzése, stb. URL: https://www.waze.com/
öl a telefonba épített GPS segítségével. Ötletük a közösségi megvalósítás, vagyis az úton lévők segítségével közölnek valós forgalmi adatokat – ingyen. Így válik lehetővé pl. a forgalmi dugók elkerülése. Így válik lehetővé a hagyományos útvonaltervezés mellett a forgalmi dugók elkerülése is. Kiegészítő szolgáltatások pl. traffipax-jelzés, útakadályok, sebesség-túllépés jelzése, stb. URL: https://www.waze.com/
- Twitter.com – ismeretségi hálózat és mikroblog-szolgáltatás. Itt a felhasználók rövid bejegyzéseket és üzeneteket hozhatnak létre, melyek segítségével tarthatják egymással a kapcsolatot vagy (pl. híres emberként) hírt adhatnak magukról. URL: https://twitter.com/
![]()
- Facebook.com –  a jelenlegi piacvezető közösségi kapcsolati szolgáltatás. A felhasználók rövid üzenetek mellett szövegeket, videókat, vagy fájlokat is küldhetnek egymásnak, illetve hírt adhatnak magukról. A felhasználási feltételek ingyenesek, de az ott megjelenő hirdetésekért pénzt kell letenni. A bejegyzések mellett megjelentek a játékok, a nyitott és zárt csoportok, illetve egyéb kényelmi szolgáltatások is. URL: https://www.facebook.com/
a jelenlegi piacvezető közösségi kapcsolati szolgáltatás. A felhasználók rövid üzenetek mellett szövegeket, videókat, vagy fájlokat is küldhetnek egymásnak, illetve hírt adhatnak magukról. A felhasználási feltételek ingyenesek, de az ott megjelenő hirdetésekért pénzt kell letenni. A bejegyzések mellett megjelentek a játékok, a nyitott és zárt csoportok, illetve egyéb kényelmi szolgáltatások is. URL: https://www.facebook.com/
- Amazon.com – a könyv- és egyéb vásárlások alapján a cég elemzi a felhasználók szokásait, az eddig látogatott oldalakat és a látogatások hosszát, illetve a pénzköltésük alapján személyre szabott ajánlatokat is ad a felhasználónak. URL: https://www.amazon.com/![]()
- Üzlet forgalomelemzése: az egyszerű pénztárgépek ideje elmúlt. A klasszikus kisboltok forgalmát 1-2 eladó is átlátja, de a nagyobb üzleteknél a pénztárgépek már össze vannak kötve egy központi számítógéppel. Ez egyrészt a beolvasott vonalkód alapján adja az árakat, valamint jelzi azt is, hogy az egyes termékek mennyire fogynak. Így jól látható, hogy melyik terméket kell hamarosan újra feltölteni. A kicsit komolyabb gépek már kész rendelési listát is összeállítanak, amit igény szerint el is lehet küldeni a beszállítónak. További ötlet, hogy az egyes cikkek fogyása alapján láthatóvá válnak az aktuális vásárlói trendek, így érezhető, hogy melyik termékből érdemes többet előrendelni.

- Kereskedelmi hűségkártyák: Az egyes kis- és nagykereskedelmi láncok előszeretettel adnak a vásárlóiknak hűségkártyákat. (pl: Lidl, Tesco, Metro, Spar, Penny, DM, Rossmann, stb. - kép forrása: saját telefonom) Ezek több célra is alkalmasak! Egyrészt maguk a vásárlók a kártya bemutatása után kaphatnak némi kedvezményt egyes termékekre, ami jó a vásárlónak, hiszen árengedményt kap; másrészt jó az üzletnek is, hiszen így a konkurencia helyett inkább odacsábítja a vevőt. Most lépjünk túl az általánosságokon, hogy az áruházi katalógusokat (főleg) a hűségkártyával rendelkezők kapják vagy a katalógusokban csak nekik szóló árengedményes termékeket hirdethetnek. Azonban az egyes vevő hűségkártyájának forgalmi adatai alapján lehet személyes profilokat (is) összeállítani. Így pl. ha az adott vevő gyakran vesz egy bizonyos típusú joghurtot, akkor neki (akár személyre szabottan) érdemes kedvezményt adni arra a joghurtra; esetleg egy újabb íz megjelenésekor érdemes akár ingyenes termékmintát ajánlani. A nagyobb láncok egyre inkább túllépnek a plasztikkártyákon és helyettük applikációt kínálnak. Ezek jellemzően ingyenesen letölthetők, majd egyszeri beregisztrálás után már ontják is a friss adatokat a vevő mobiljára. Ennek része lehet az üzletkereső, a hagyományos papír-alapú katalógusok helyetti online verzió, továbbá egyre több alkalmazás kínál szabadon szerkeszthető bevásárlólistát is.
- Gyorséttermi kupokon: Az egyes étteremláncok (pl: McDonald’s, Burger King) régebben még a postaládákba dobálták bele némi kedvezményt adó kuponokat. Ezek ideje már lejárt, így ezt a módszert szintén felváltották az online applikáción keresztül elérhető, akár személyre is szabható ajánlatok. Így a fogyasztó egyrészt letöltheti az ingyenes applikációt, másrészt az általános ajánlatok mellett az eddigi fogyasztási adatait elemezve kaphat személyre szabott ajánlatokat is. Több lánc már kínál előrendelést is, hogy a konkrét étterembe érkezés közben már le lehessen adni a rendelést, amit odaérkezéskor már csak át kelljen venni. A fizetés lehet akár előre is, akár beérkezéskor. Ebben benne van a 2020-as évekre teljesen elfogadott ételfutár szolgáltatások lehetősége is.
- Banki adatok elemzése: az egyes bankoknak nagy lehetőséget nyújtanak az számlatulajdonosaik által használt bankkártyák költési adatai. Nagy mennyiségű adatszűréssel lehetséges kielemezni, hogy az ügyfelek nagyon rákaptak egy adott boltra vagy szolgáltatásra. Így a bank felveheti az adott véggel a kapcsolatot, hogy az adott bak ügyfeleinek érdemes lenne némi kedvezményt nyújtani. Ez lehet akár egy gyorsétterem, akár egy kiskereskedelmi üzlet, akár egy benzinkút, vagy bármi más. További lehetőségként felmerül az is, hogy az adott ügyfél mobiltelefonjának lokációs adatelemzése alapján a bank tippet adhat, miszerint az ügyfél közelében lévő adott étteremben éppen most kedvezménnyel vásárolható meg a kedvenc étele.
- Karbon lábnyom: a fiataloknak egyre fontosabb a tudatos fogyasztás mellett az is, hogy minél kisebb karbon lábnyomot hagyjanak, tehát minél kevésbé terheljék a környezetüket. Egyes adatelemző cégek erre is kínálnak megoldást, így is segítve a környezet-tudatos vásárlókat.
Felhasznált irodalom:
- http://www.origo.hu/tudomany/20131014-big-data-adatelemzes-tudomany-adatbanyaszat-informatika.html
- http://hvg.hu/cimke/Big_Data
- https://www.it-services.hu/hirek/mi-az-a-big-data/
- https://hu.wikipedia.org/wiki/Big_data
- http://piackutatas.blog.hu/2012/10/03/mit_jelent_es_mire_jo_a_big_data
- https://www.bme.hu/hirek/20150202/Big_data_adatvezerelt_kulturank_uj_mozgatorugoja
- http://hvg.hu/kkv/20170223_Starschema_sikersztori
- http://hvg.hu/vallalat_vezeto/20170105_big_data_starschema
- http://hvg.hu/vallalat_vezeto/20150812_Akik_sikerrel_lovagoljak_meg_a_big_datah
- http://www.uti.bme.hu/
- http://www.starschema.hu/
- http://www.technokrata.hu/www/2016/01/12/ettol-fugg-hogy-kiket-latsz-a-tinderen/
- https://wmn.hu/elet/30503-mennyit-er-a-randi-ha-tinder-ezert-bucsuztam-el-harom-ferfi-utan-tinderorszagtol
- http://www.usxpress.com/
- https://prezi.com/hprqde44scul/big-data-avagy-mit-lehet-kihalaszni-az-adatok-oceanjabol/
- https://lexunit.hu/blog/mi-az-a-big-data-es-mire-hasznaljuk/
- https://docs.microsoft.com/hu-hu/azure/architecture/guide/architecture-styles/big-data
- https://edit.elte.hu/xmlui/handle/10831/37943
- https://www.icas.com/thought-leadership/technology/10-companies-using-big-data
- https://onbrands.hu/marka-es-trend/2020/11/innovacio/a-big-data-felforgatja-az-eletunket-ot-trend
- https://lexunit.hu/blog/mi-az-a-big-data-es-mire-hasznaljuk/
- https://www.oracle.com/big-data/what-is-big-data/
© TFeri.hu, 2017. márc.
Felújítva: 2017.okt., 2019.okt., 2021.okt., 2022.jún.és 2023.ápr.